 É sabido que em redes sociais, em nível mundial, são produzidos milhões de textos diariamente e há menções aos mais diversos tópicos. Uma das redes que permitem com que haja engajamento entre usuários por termos sendo mencionados é o Twitter, que também é uma das plataformas mais populares. Dessa forma, entender o que a audiência está falando sobre um acontecimento, uma persona pública, uma empresa, é uma oportunidade.
É sabido que em redes sociais, em nível mundial, são produzidos milhões de textos diariamente e há menções aos mais diversos tópicos. Uma das redes que permitem com que haja engajamento entre usuários por termos sendo mencionados é o Twitter, que também é uma das plataformas mais populares. Dessa forma, entender o que a audiência está falando sobre um acontecimento, uma persona pública, uma empresa, é uma oportunidade.
Neste artigo vamos mostrar um exemplo de detecção de tópicos relacionados aos tweets que fazem menção ao – possível candidato à reeleição Jair Messias Bolsonaro, utilizando tweets coletados em um intervalo de tempo pequeno, de 30 minutos, em um dia escolhido aleatoriamente.
Detecção de Tópicos via Aprendizado de Máquina
Existem diversos métodos de realizar a detecção de tópicos, que podem ser implementados utilizando algoritmos de Aprendizado de Máquina, entre os quais destacam-se para nosso caso as técnicas de Aprendizado não supervisionado, que são técnicas que usam algoritmos que não precisam da inserção de dados pré-classificados para agrupar os dados. Entre os principais para este tipo de aplicação estão: Alocação Latente de Dirichlet – LDA e K-means. No presente artigo, nosso foco será no LDA.
Alocação Latente de Dirichlet – LDA
O algoritmo de Alocação Latente de Dirichlet (LDA) é uma técnica de modelagem de tópicos amplamente utilizada em processamento de linguagem natural e mineração de textos. Desenvolvido por David Blei, Andrew Ng e Michael Jordan em 2003, o LDA é baseado em modelos probabilísticos que tentam descobrir tópicos subjacentes em um conjunto de documentos.
Esse algoritmo é baseado em um modelo probabilístico, no qual assume-se que cada documento estudado é constituído por uma combinação de tópicos e que cada tópico corresponde a uma distribuição de palavras. Assim, as palavras relevantes para cada tópico são definidas utilizando inferência Bayesiana. Finalmente, a quantidade de tópicos em um modelo LDA pode ser determinada de acordo com a similaridade semântica entre as palavras em um tópico, onde a combinação que apresentar o maior score de coerência será a adotada.
Em um alto nível, o processo de treinamento do LDA pode ser resumido da seguinte maneira:
- Inicialização: Atribuir aleatoriamente palavras a tópicos nos documentos;
- Iterações: Para cada palavra em cada documento, reatribuir o tópico com base em certas probabilidades;
- Inferência: Após várias iterações, as distribuições de tópicos nos documentos e as distribuições de palavras nos tópicos convergem para valores que representam as relações subjacentes entre tópicos e documentos;
- Resultado: Os resultados do LDA incluem a distribuição de tópicos em cada documento e a distribuição de palavras em cada tópico. Isso permite a interpretação dos tópicos e a identificação das palavras mais representativas de cada tópico;
O LDA é útil para descobrir padrões latentes em grandes conjuntos de documentos, sendo aplicado em diversas áreas, como organização automática de grandes coleções de textos, recomendação de conteúdo e análise de sentimentos. Sua flexibilidade e interpretabilidade fazem dele uma ferramenta valiosa para explorar e entender a estrutura de grandes conjuntos de dados textuais.
Resultados
Os resultados da modelagem LDA podem ser vistos nas figuras 1 e 2, abaixo, e foram obtidos utilizando a biblioteca pyLDAvis, do Python. A Figura 1 é um diagrama de linha que mostra o resultado da coerência semântica variando em função do número de tópicos. O maior valor de coerência obtido foi para 23 tópicos, com um valor de coerência de ~ 0,425.
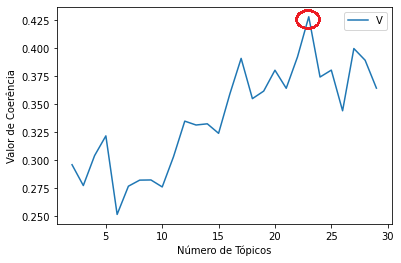
Figura 1 – Coerência semântica dos agrupamentos.
A Figura 2 é composta de um diagrama que mostra a distância multinomial entre os tópicos (esquerda) sendo que quanto maior a distância entre os círculos, menor a similaridade do seu contexto e quanto maior o diâmetro do círculo, maior a frequência do tópico entre os textos coletados. O Círculo marcado em vermelho é o tópico selecionado para análise e as palavras mais relevantes dele aparecem no diagrama de barras à direita do gráfico. Observa-se que para o tópico 1, os termos mais relevantes são: bolsonaro, governar, ciência, absorvente, vetar. Muito provavelmente esses são termos referentes ao veto do governo à distribuição de absorventes para mulheres carentes, fato que foi inclusive bastante noticiado pela mídia.
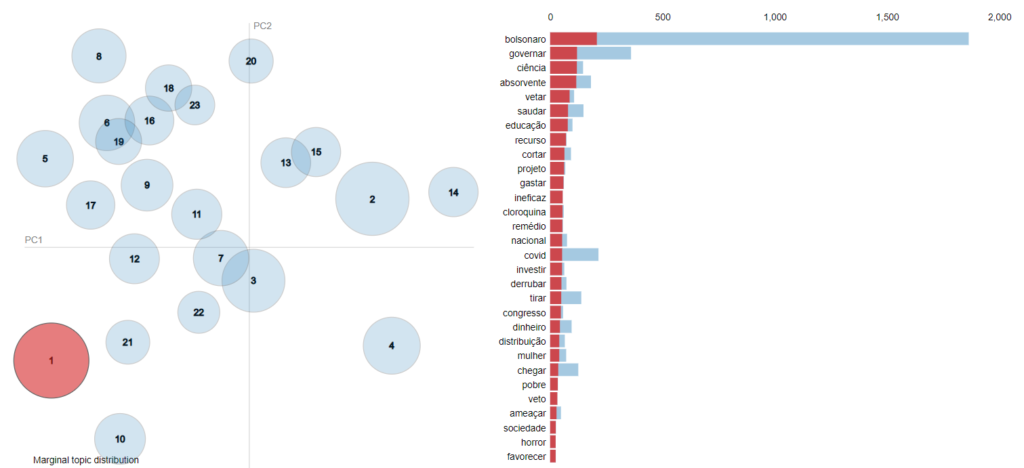
Figura 2 – Visualização do modelo LDA.
Finalmente, o método LDA permite uma fácil e rápida visualização de tópicos, facilitando o monitoramento da opinião pública sobre diversos temas de interesse. No presente artigo, apresentamos apenas a parte de identificação dos tópicos, mas existem outras técnicas de mineração de opinião que podem ser aplicadas após a identificação dos tópicos, entre elas podemos citar a análise de sentimento, tema para outro artigo. Além disso, o método LDA pode ser combinado com outras métricas e algoritmos de agrupamento de tópicos e não necessita dos longos tempos de implementação necessários em métodos de aprendizado de máquina supervisionados.
Principais referências:
pyLDAvis, Modelagem de tópicos LDA, Dissertação – Abordagem para seleção de tópicos