
Algumas empresas produzem um volume muito grande de documentos e informações, que precisam ser extraídas para posterior controle e acompanhamento. Em um contrato é necessário saber das partes seus nomes, endereços, documentos, valor do contrato, local do contrato, entre muitas outras. Naturalmente que alguém precisar ler o documento e digitar essas informações em um sistema é impraticável, por isso se utiliza uma série de técnicas para extração desses dados: uma delas, dentro do que se chama de Processamento de Linguagem Natural, que trata do entendimento da linguagem humana por máquinas, é o Reconhecimento de Entidades Nomeadas (NER, do Inglês: Named Entity Recognition). Essa técnica permite classificar os itens de interesse (as entidades), de forma que seja possível extrair automaticamente um grande volume de informações dos textos analisados.
APRENDIZADO DE MÁQUINA
Em linguagens como o Python, NER pode ser empregado utilizando bibliotecas como spaCy, que permitem aplicar Aprendizado de Máquina para treinar a identificação das entidades. Nesse caso trata-se de aprendizado supervisionado, onde documentos com dados rotulados são processados por um algoritmo, que gera um modelo treinado. Um dos métodos utilizados no treinamento envolve o emprego de Redes Neurais Convolucionais. Nessa etapa são especificados os chamados hiperparâmetros de treinamento, como taxa de diluição, tamanhos de lotes de treinamento, taxa de aprendizado, número de iterações, entre outros.
EXTRAÇÃO DE DADOS DE CONTRATOS
Dado um input de documentos devidamente rotulados, como na Figura 1, os mesmos foram submetidos a um processo de treinamento por Redes Neurais, de onde foi obtido um modelo treinado para identificar entidades referentes a elementos do endereço em um contrato, tais como: logradouro, CEP, bairro, quadra, número, etc. A Figura 2 abaixo apresenta a curva da função de perda (loss function), obtida no treinamento, a partir do método de Gradiente Descendente Estocástico (SGD do inglês: Stochastic Gradient Descent). Essa curva pode ser interpretada como o erro que a rede neural obtém ao tentar fazer uma previsão em dado momento do treinamento. Observa-se que durante as iterações mais próximas de zero, esse erro é elevado e vai reduzindo drasticamente com o decorrer do processamento. Isso é uma característica de um processo de treinamento bem sucedido.

Figura 1 – Documento com dados rotulados.
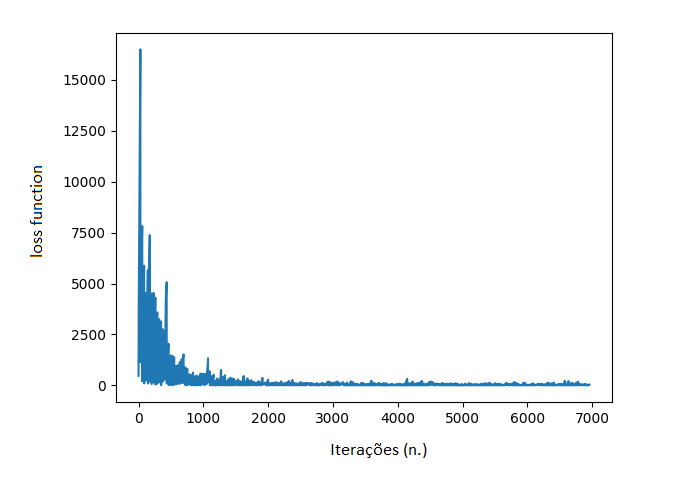
Figura 2 – Função perda calculada pelo SGD.
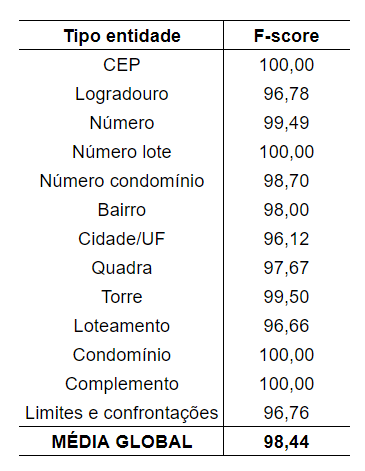
Com um modelo de aprendizado de máquina treinado, podemos submeter novos documentos para testar na prática se nossos resultados são satisfatórios com o treinamento. Esses resultados, são apresentados na Tabela 1 abaixo, que mostra o F-score dos testes realizados por categoria e globalmente, onde é possível observar que obtivemos um F-score com uma média global de 98,44, sendo este um resultado bastante positivo, pois o F-score é uma média harmônica entre a precisão e a sensibilidade do modelo, o que quer dizer que nosso modelo é bastante capaz de identificar os itens dos documentos de forma correta.
Tabela 1 – Resultados para Reconhecimento de Entidades Nomeadas.
NER é uma técnica bastante flexível que quando aplicada em conjunto com práticas de aprendizado de máquina permite uma identificação correta e segura dos mais distintos elementos de interesse em documentos. Também, o uso de técnicas de aprendizado de máquina torna o processo de implementação da NER muito mais rápido, tornando esta uma solução indispensável para análise de grandes volumes de documentos.
Principais referências: Redes Neurais Convolucionais, Como as Redes Neurais aprendem?, Gradiente Descendente.